
Incident report for August 16, 2024 - Function execution outage
Dan Farrelly· 8/16/2024 · 6 min read
On August 16, 2024 (UTC), Inngest experienced an outage that prevent functions execution from successfully running. Specifically, our forward proxy for all function invocation requests, internally known as the “SDK Gateway,” stopped handling requests properly.
The SDK Gateway services log each request for audit purposes and ran out of disk space due to increased load and logrotate running too infrequently, causing the service to stall. The issue was fixed on each instance to bring them back online and prevent future failures of this type.
We sincerely apologize for incurring this downtime. System reliability is of the utmost importance for us, and we will ensure this type of failure does not happen again.
Full timeline, root cause and corrective actions are detailed below.
Timeline
- 2024-08-16 00:05 UTC - SDK Gateways stop fulfilling requests. Function execution is failing.
- 2024-08-16 00:10 UTC - On-call engineers are paged with an alert citing high volume of function execution failures.
- 2024-08-16 00:25 UTC - Issue is pinpointed to the SDK Gateways. Team attempts to restart instances to reset state.
- 2024-08-16 00:38 UTC - Executor services are scaled down to zero to prevent thundering herd issues when SDK Gateways are brought back online.
- 2024-08-16 00:51 UTC - Manual intervention to clear disk space begins. Internal service discovery IPs are rotated. Function execution is partially restored.
- 2024-08-16 01:01 UTC - All SDK Gateways are back online. New public IPs are issued.
- 2024-08-16 01:51 UTC - One SDK Gateway is found not to be functioning correctly and is rebooted and service discovery IPs are rotated.
- 2024-08-16 04:40 UTC - Networking issues reported by Vercel customers.
- 2024-08-16 04:47 UTC - New static IP addresses created and process of configuration begins. New static IPs are published to our IP v4 public list for partners.
- 2024-08-16 05:30 UTC - New SDK Gateways with static IPs start to roll out.
- 2024-08-16 05:45 UTC - All SDK Gateways are rolled out. Function execution is fully restored.
- 2024-08-16 06:02 UTC - Additional SDK Gateways are added for extra capacity and redundancy.
Root Cause
The SDK Gateway forward proxy handles all egress HTTPS traffic from our function “executor” service to ensure consistent IP addresses are used for outbound traffic to our various cloud provider partners, such as Vercel. Our “executors” are responsible for pulling work off internal queues to invoke user functions at whatever URL they may be hosted at. These executors run within our Kubernetes cluster, scale depending on load, and IPs are ephemeral, so the SDK Gateway is used as a proxy for outbound requests. The SDK Gateway runs a group of machines, each with static IPs assigned.
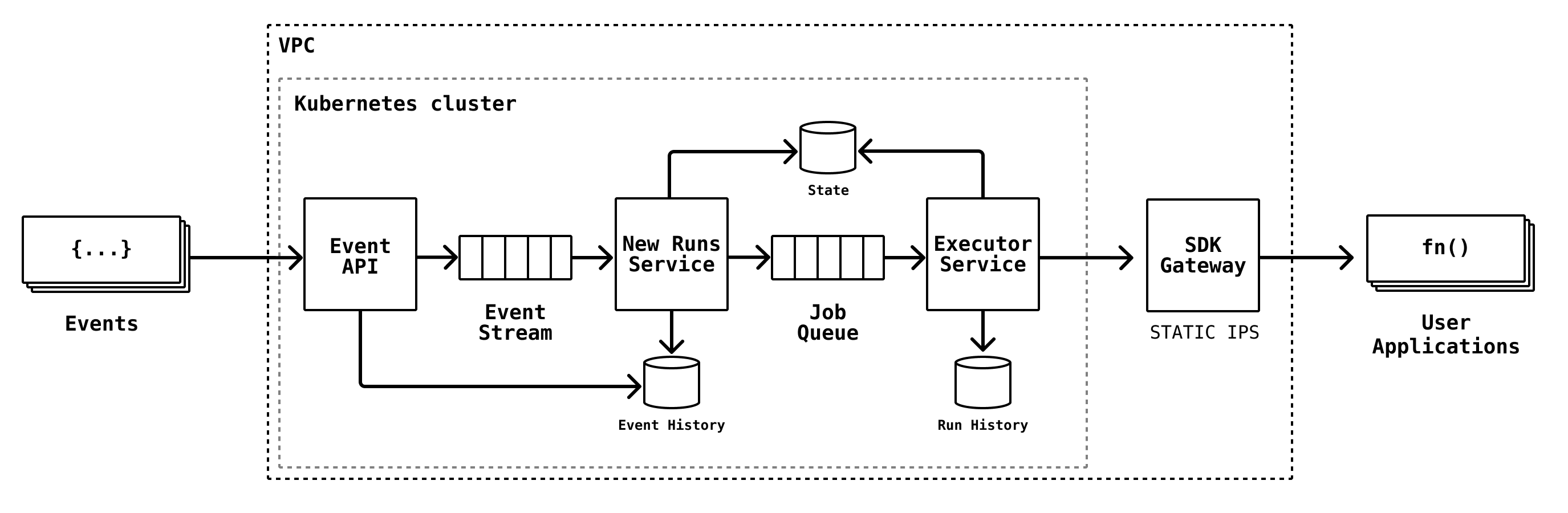
For audit purposes, the SDK Gateway logs details on every request it makes. Due to increased throughput beginning the morning of Thursday 15th, instances started running out of disk space. The lack of disk space prevented logging, which caused the processes running on the instances to hang. Log rotation was not properly configured on these instances. Fixing this issue immediately require manual intervention. Log rotation has since been configured to run hourly on these instances.
Each SDK Gateway was rebooted which released each of their public IP addresses. The SDK Gateways were fully functional again, but our public IP addresses were now out of date. Execution resumed for many customers, but customers hosting functions on Vercel continued to see issues due to the new IPs being blocked by Vercel's firewall.
To prevent future issues with partners like Vercel, we created a pool of static IPs to assign to our SDK Gateway instances. After assigning these new static IPs, we updated our public list of IP addresses that are fetched periodically by partners to ensure the allow list is up to date. We've also acquired a permanent /24 block of IPs which we will utilize for our infrastructure.
Additionally, while the SDK Gateway service was horizontally scaled to handle peak throughput with overhead, we increased the number of replicas for additional capacity and resiliency.
Unfortunately the process of these manual interventions and coordination with upstream providers took longer than expected, delaying the resolution for customers.
As the service returned to normal capacity, users with large backlogs started executing work at very high throughput. This high throughput caused Vercel to block a subset of IPs for select Vercel customers. We since worked with these mutual customers and the Vercel infrastructure team to resume normal execution. We will continue to work with the Vercel team to ensure high volume users can proceed as expected.
Impact
Function execution was down for 46 minutes, and degraded on Vercel for 4 hours 54 minutes.
Inbound events sent to Inngest were not lost. The Inngest Event API and event ingestion services are decoupled from function execution. All functions can be replayed.
For more information about replaying failed functions during the outage, please read our Replay guide. Users can select to only replay functions that failed during this time range.
Corrective actions
- Improve alerting via Datadog. We currently have liveness checks, and will add alerts on:
- Network packets, CPU, disk space
- Add improved log rotation in the instance AMI.
- Increase number of SDK Gateway replicas for additional redundancy with an expanded set of static IPs that can be assigned.
- Stagger rotation of SDK Gateway services to ensure unforeseen failures do not occur at the same time.
- Perform rehearsals with all engineers on restoring issues with SDK Gateways.
- We have purchased a /24 block of public IP addresses to use for future SDK Gateways and outbound services. This will give us greater flexibility and an easier way to provide IP ranges to cloud provider partners.
In closing
We sincerely apologize for this incident. System reliability is our top priority, and we recognize that this downtime represents the most significant outage in the last three years.
We do not take this matter lightly. In addition to implementing corrective actions, we will conduct an additional audit to identify and address potential points of failure in our system. Our commitment to investing in reliability and resilience remains steadfast to prevent future issues.
Thank you for your understanding. If you have any questions, please don't hesitate to reach out to our support team.
Chat with a solutions expert
Connect with us to see if Inngest fits your queuing and orchestration needs.
Contact us